
Communication technologies enable coordination among connected and autonomous vehicles (CAVs). However, it remains unclear how to utilize shared information to improve the safety and efficiency of the CAV system in dynamic and complicated driving scenarios. In this work, we propose a framework of constrained multi-agent reinforcement learning (MARL) with a parallel Safety Shield for CAVs in challenging driving scenarios that includes unconnected hazard vehicles. The coordination mechanisms of the proposed MARL include information sharing and cooperative policy learning, with Graph Convolutional Network (GCN)-Transformer as a spatial-temporal encoder that enhances the agent's environment awareness. The Safety Shield module with Control Barrier Functions (CBF)-based safety checking protects the agents from taking unsafe actions. We design a constrained multi-agent advantage actor-critic (CMAA2C) algorithm to train safe and cooperative policies for CAVs. With the experiment deployed in the CARLA simulator, we verify the performance of the safety checking, spatial-temporal encoder, and coordination mechanisms designed in our method by comparative experiments in several challenging scenarios with unconnected hazard vehicles. Results show that our proposed methodology significantly increases system safety and efficiency in challenging scenarios.
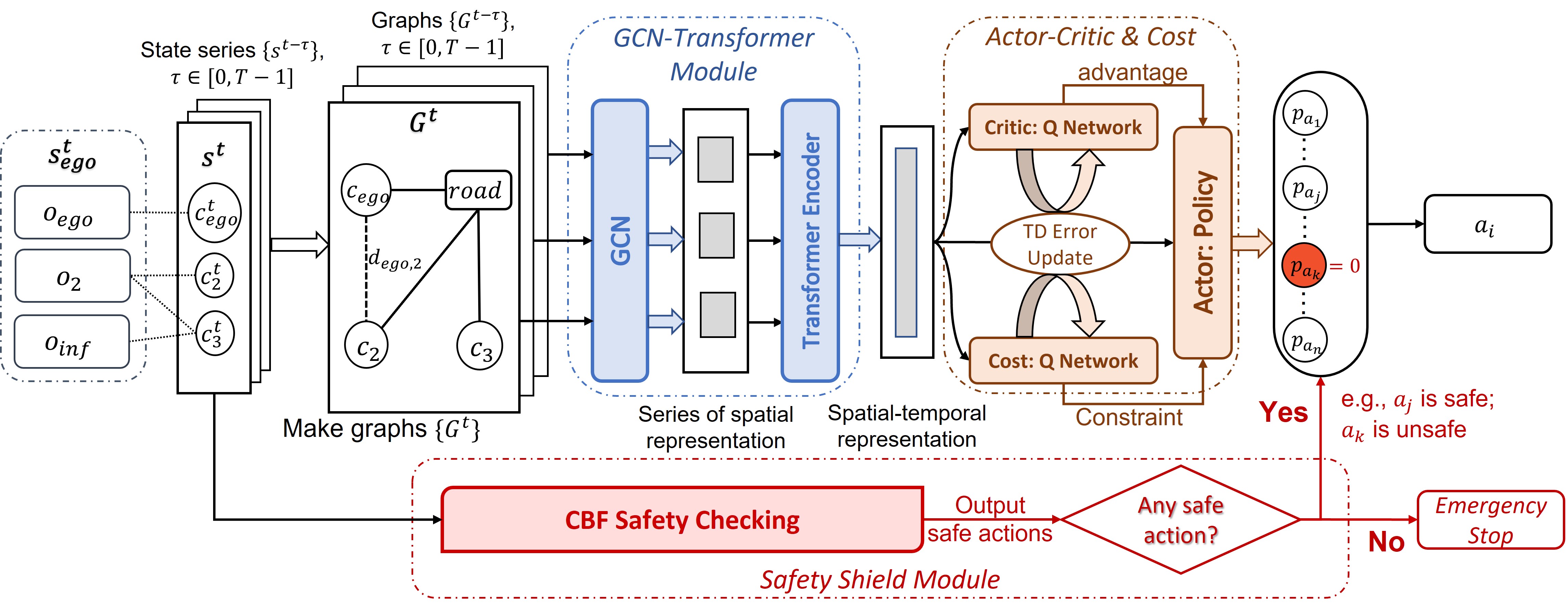
Model pipeline for a single agent. The state information as time series \( \{ s^{t-\tau} \}_{\tau} \) will be processed as graphs first and sequentially enter the GCN-Transformer module and the Actor's policy network; meanwhile, \( s^t \) is input to the CBF safety checking module for computing safe actions. During training, the outputs of GCN-Tranformer will be input to the Critic and Cost network for advantage, constraint and TD error calculation.
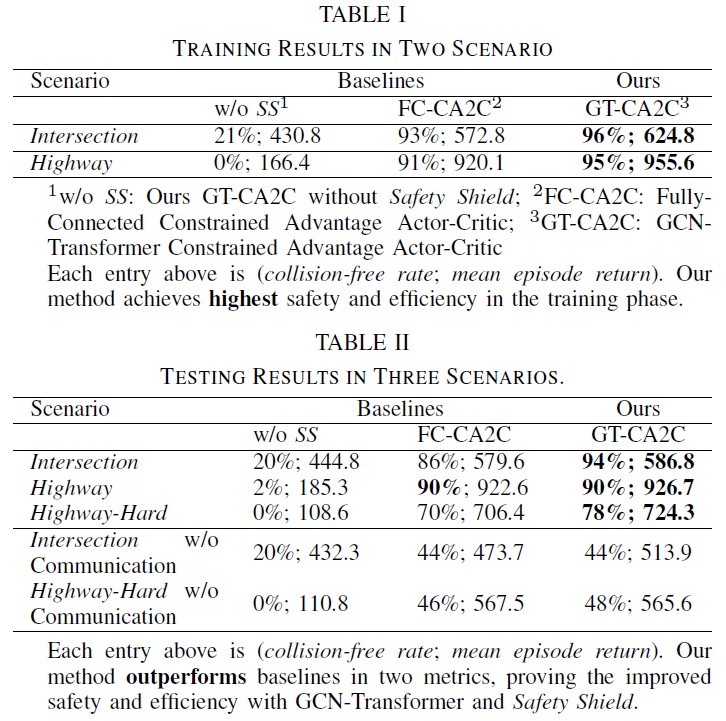
We trained our model (GCN-Transformer Constrained Advantage Actor-Critic; 'GT-CA2C' in the table 1, 2), a baseline using our model without Safety Shield ('w/o SS' in tables) and another baseline 'FC-CA2C' with fully-connected layers (replacing GCN-Transformer), constrained advantage actor-critic and Safety Shield, each on Intersection and Highway scenarios. Our method and baselines are all under the multi-agent framework in Alg. 1. Training and testing experiment results are presented in table 1 and 2. We highlight our method's top leading performance among all solutions. For each entry in tables, the left percentage is the collision-free rate in simulation; the right number is the mean episode return defined as the mean of agents' sums over stepwise rewards in every episode: \( \sum_{\epsilon=1}^{m} Avg_i {\sum_{t}{r_i^t}}/m \).
@inproceedings{zhang2023spatial,
title={Spatial-temporal-aware safe multi-agent reinforcement learning of connected autonomous vehicles in challenging scenarios},
author={Zhang, Zhili and Han, Songyang and Wang, Jiangwei and Miao, Fei},
booktitle={2023 IEEE International Conference on Robotics and Automation (ICRA)},
pages={5574--5580},
year={2023},
organization={IEEE}
}